目录
显示
AudioNotes 介绍
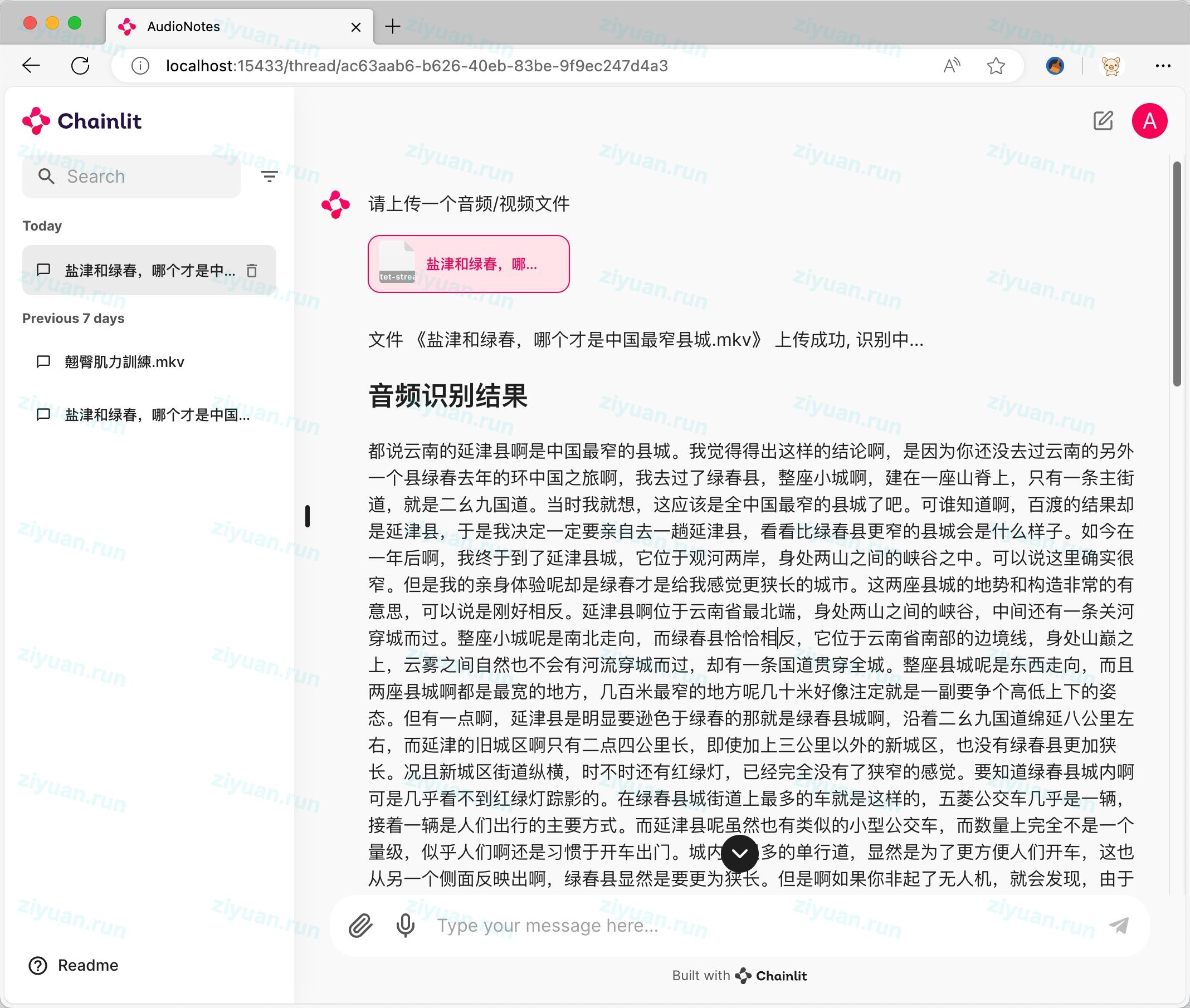
AudioNotes 是一套基于 FunASR 语音识别引擎和 Qwen2 大语言模型构建的音视频内容处理工具。该系统能从音视频文件中提取语音内容,并通过大模型技术将其整理为结构化的 Markdown 笔记,让用户能够快速获取和理解视频内容精华。
AudioNotes 亮点
- 智能转写: 利用 FunASR 技术准确识别音视频中的语音内容,支持多种语言
- 内容整理: 通过 Qwen2 大语言模型对识别文本进行智能结构化,生成易读笔记
- 交互问答: 支持用户与音视频内容进行直接对话,快速获取特定信息
- 轻量部署: 提供 Docker 一键部署与本地安装两种方式,满足不同用户需求
AudioNotes 部署教程
- 首先安装 Ollama
从官方网站 https://ollama.com/download 下载并安装适合您系统的 Ollama 软件包 - 获取所需语言模型
拉取阿里巴巴开发的 Qwen2 7B 模型,模型详情可访问 https://ollama.com/library/qwen2 - 选择部署方式
Docker 部署方式(推荐)
curl -fsSL https://github.com/harry0703/AudioNotes/raw/main/docker-compose.yml -o docker-compose.yml docker-compose up服务启动后访问 http://localhost:15433/
默认登录凭据:用户名 admin,密码 admin(可在 docker-compose.yml 中修改)本地部署方式
需要准备可访问的 PostgreSQL 数据库,然后执行:
conda create -n AudioNotes python=3.10 -y conda activate AudioNotes git clone https://github.com/harry0703/AudioNotes.git cd AudioNotes pip install -r requirements.txt将
.env.example文件复制为.env并修改相关配置
服务启动后访问 http://localhost:8000/
默认登录凭据:用户名 admin,密码 admin(可在 .env 文件中修改)
AudioNotes 获取链接
1. 转载请保留原文链接谢谢!
2. 本站所有资源文章出自互联网收集整理,本站不参与制作,如果侵犯了您的合法权益,请联系本站我们会及时删除。
3. 本站发布资源来源于互联网,可能存在水印或者引流等信息,请用户擦亮眼睛自行鉴别,做一个有主见和判断力的用户。
4. 本站资源仅供研究、学习交流之用,若使用商业用途,请购买正版授权,否则产生的一切后果将由下载用户自行承担。
5. 联系方式(#替换成@):feedback#ziyuan.run
评论(0)